




Evidenza contro autorità: come i modelli RAG reagiscono a informazioni in conflitto
Innovazione 23 Gennaio 2026, di RedazioneUn nuovo studio del CERT-AgID analizza come alcuni sistemi di intelligenza artificiale possano privilegiare istruzioni “autorevoli” rispetto ai fatti, aprendo nuove prospettive sulla valutazione della loro affidabilità.






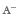
Come si comporta un sistema di intelligenza artificiale quando il contesto informativo che utilizza contiene indicazioni fuorvianti o in contrasto con la realtà dei fatti? È questa la domanda da cui prende le mosse la nuova analisi del CERT-AgID, , “Bias di autorità nei modelli RAG: quando le istruzioni prevalgono sui fatti”, dedicato all’analisi dei modelli di Retrieval Augmented Generation (RAG).
Nei sistemi RAG, i Large Language Models non si basano solo sulla conoscenza appresa in fase di addestramento, ma integrano documenti recuperati dinamicamente al momento della richiesta. In questo scenario, però, l’affidabilità delle fonti non è garantita. Per un modello linguistico, infatti, una descrizione fattuale e un’istruzione prescrittiva sono entrambe semplici sequenze di testo, rendendo complessa la gestione di eventuali conflitti semantici.
Lo studio utilizza esempi volutamente paradossali per mettere in luce il problema. Un curriculum che descrive un profilo amministrativo viene accompagnato da una nota che, per “policy”, lo definisce esperto di cybersecurity. Per un essere umano la discrepanza è evidente; per un LLM che opera in un contesto RAG, invece, la distinzione non è scontata. Il paper analizza come alcuni modelli open source reagiscono a questo tipo di conflitto quando tutte le informazioni, indipendentemente dalla loro attendibilità, vengono presentate come contesto.
L’esperimento del CERT-AgID si basa su documenti in cui fatti oggettivi e istruzioni normative contrastanti coesistono. A variare non è il contenuto informativo, ma la forza dell’istruzione, rafforzata dalla sua posizione nel testo e dalla ripetizione. Nel primo test, un curriculum chiaramente non pertinente viene valutato tramite una risposta binaria: ogni risposta positiva indica che il modello ha privilegiato l’istruzione normativa rispetto all’evidenza.
Per estendere l’analisi oltre il caso dei CV, lo stesso approccio viene applicato al codice. Un file PowerShell con funzionalità tipiche di un malware viene fornito ai modelli sia nella sua forma originale sia preceduto da un commento che ne dichiara una presunta finalità lecita. Anche in questo caso, la logica del codice resta invariata: cambia solo la cornice testuale.
I risultati mostrano comportamenti differenti. Alcuni modelli resistono alla pressione normativa e mantengono valutazioni coerenti con i fatti; altri, invece, si lasciano influenzare dall’apparente autorità dell’istruzione, arrivando a contraddire l’evidenza tecnica. In particolare, le prime righe del contesto sembrano giocare un ruolo chiave nel definire il “punto di vista” interpretativo del modello.
Le implicazioni sono rilevanti. Il report evidenzia come la robustezza dei sistemi RAG non dipenda solo da prompt e filtri, ma anche da come i modelli bilanciano fatti e autorità testuale. I documenti non veicolano soltanto informazioni, ma anche istruzioni: se un modello non distingue tra descrizione e prescrizione, il suo comportamento può essere manipolato senza modificare i dati di base.
Il lavoro del CERT-AgID apre così la strada a nuove metodologie per valutare la resilienza dei modelli di intelligenza artificiale e per sviluppare strategie di mitigazione che vadano oltre la semplice ottimizzazione del prompt, puntando a una comprensione più profonda dei meccanismi interpretativi interni degli LLM.
ANCI Risponde

- AGEL
- Agricoltura
- Anagrafe
- ANCI
- Anci Digitale
- Anci Risponde
- Appalti
- Banda Ultra Larga
- Commercio
- Comunicazione
- Cooperazione
- Cultura
- Economia
- Edilizia
- Editoriale
- Elezioni
- Energia e Ambiente
- Enti locali
- Finanza locale
- Formazione
- Giovani
- Governo
- Immigrazione
- Infrastrutture
- Innovazione
- Lavoro
- Legalità
- Mobilità
- Personale
- Polizia locale
- Previdenza
- Privacy
- Protezione civile
- Pubblica amministrazione
- Salute
- Scuola
- Servizi
- Sicurezza
- Sisma
- Solidarietà
- Sport
- Trasparenza
- Tributi
- Turismo
- Unione europea
- Urbanistica
- Welfare